In looking into the world of triple stores there, exists very little in the way of traditional web communities discussing and comparing them. Most of the discussion appears to happen in academic journals, which would make sense as their widest use is in academia. A good starting place is comparing some of the available triple stores with the goal of producing a modern web application that would ideally have a mostly javascript client-side that is querying and updating a triple store on the backend.
I picked a small sample of open source, actively maintained and easy to install stores to run through a series of tests.
| Name | License | Deployment | Language |
|---|---|---|---|
| Apache Fuseki | Apache License 2 | Standalone or WAR | Java |
| Blazegraph | GPLv2 or commercial | Standalone or WAR | Java |
| Sesame | BSD | WAR | Java |
| Virtuoso | GPL | Native | C |
Using these four, I will compare them and discuss general merits that could be applied against any store you wish to test. The categories will be.
- Installation/Configuration
- Admin Interface
- Data Loading
- Data Exploration
- REST
- Feature Support
- Performance
- Production Readiness
Installation/Configuration
I wanted a similar environment for all of the testing, so I chose to deploy each of these into a Virtualbox VM with identical specs. The host of these VMs was a mid 2012 Mac Pro with 2 x 2.4 GHz 6-core Xeon processors and 16GB of ram. Each VM was given 8GB of ram and 4 processors, and while performance tests were running only a single VM would be active at a time. I chose CentOS 7 as the operating system and Tomcat as the application server for the stores that needed it. Given the choice to run as a standalone or WAR file I used the WAR files with Tomcat.
Fuseki
Fuseki is a web front-end provided for the Apache Jena RDF tools, I downloaded the Fuseki2 tar and followed the rather terse installation instructions.
Fuseki as a Web Application
Fuseki can run from a WAR file.
FUSEKI_HOME is not applicable.
FUSEKI_BASE defaults to /etc/fuseki which must be a writeable directory.
It is initialised the first time Fuseki runs, including a Apache Shiro security
file but this is only intended as a starting point.
It restricts use of the admin UI to the local machine.
Dropping the WAR into Tomcat’s folder and creating a /etc/fuseki folder with Tomcat as the owner appeared to do the trick, except that the admin interface was missing some elements. It took some investigation through firefox’s inspect element to see that it was attempting to load additional resources and was getting a 403 Forbidden from the server. Investigating inside the /etc/fuseki folder there was a shiro.ini file with basic permissions set. I’ve never messed with Apache Shiro security, but my assumption was that by port forwarding into the VM the server didn’t see the request as coming from localhost and was denying access. As a simple fix I allowed all access by uncommenting the line to allow all access. This solved the problem and I had full access to the admin interface.
Installation was mostly straight forward, although due to my deployment setup on a VM I had some rather opaque security issues.
Blazegraph
Blazegraph was another simple Java webserver deployment. Following the instructions here, I extracted the WAR and dropped it in Tomcat’s folder. After restarting Tomcat the admin interface was fully accessible and working.
Sesame
Sesame had complete installation instructions and good descriptions of the different options for installation. Sesame can be slightly confusing as it is used by other triple stores as middleware for programming interfaces or implementing REST, however it has a native triple store built in and can function as a server on its own. Installation was a simple matter of extracting the 2 WAR files into Tomcat’s webapp folder and restarting. After Tomcat launched back up both the SPARQL endpoint and the workbench were accessible.
Virtuoso
Virtuoso was the only non-Java server I was testing, however with any experience compiling software its installation should be a breeze. The requirements to build are clearly listed with versions in the installation instructions on the github repository. After insuring they were all the proper version, the make and install went smoothly. After finding the executable and pointing it to the default config the admin interface was accessible.
Admin Interface
The admin interface is an important tool for people new to graph databases and should ideally provide you not just with a way to manage the graph, but also to query, inspect and load data into it.
Fuseki
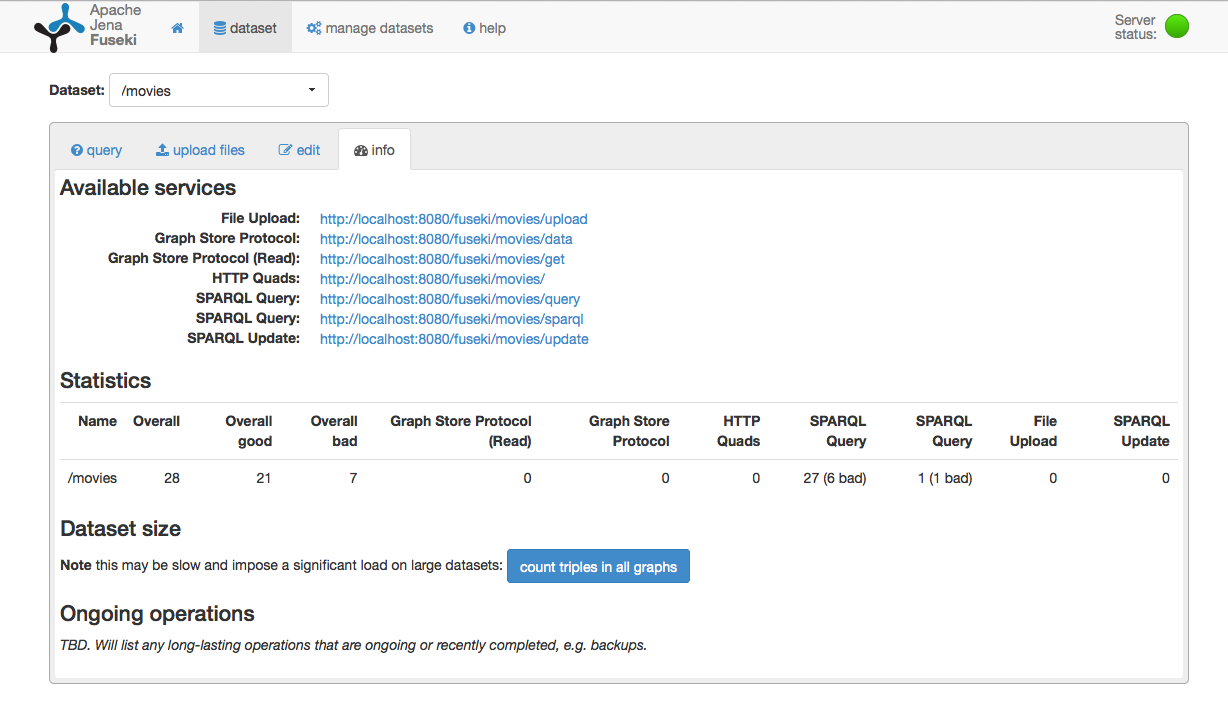
The Fuseki admin interface is very responsive and uses AJAX calls for various things. This can cause nothing to appear if your permissions are not set up properly. It has basic controls to create new datasets, backup datasets, see how many queries have been run, upload data, and a very fully featured SPARQL query writer.
Blazegraph
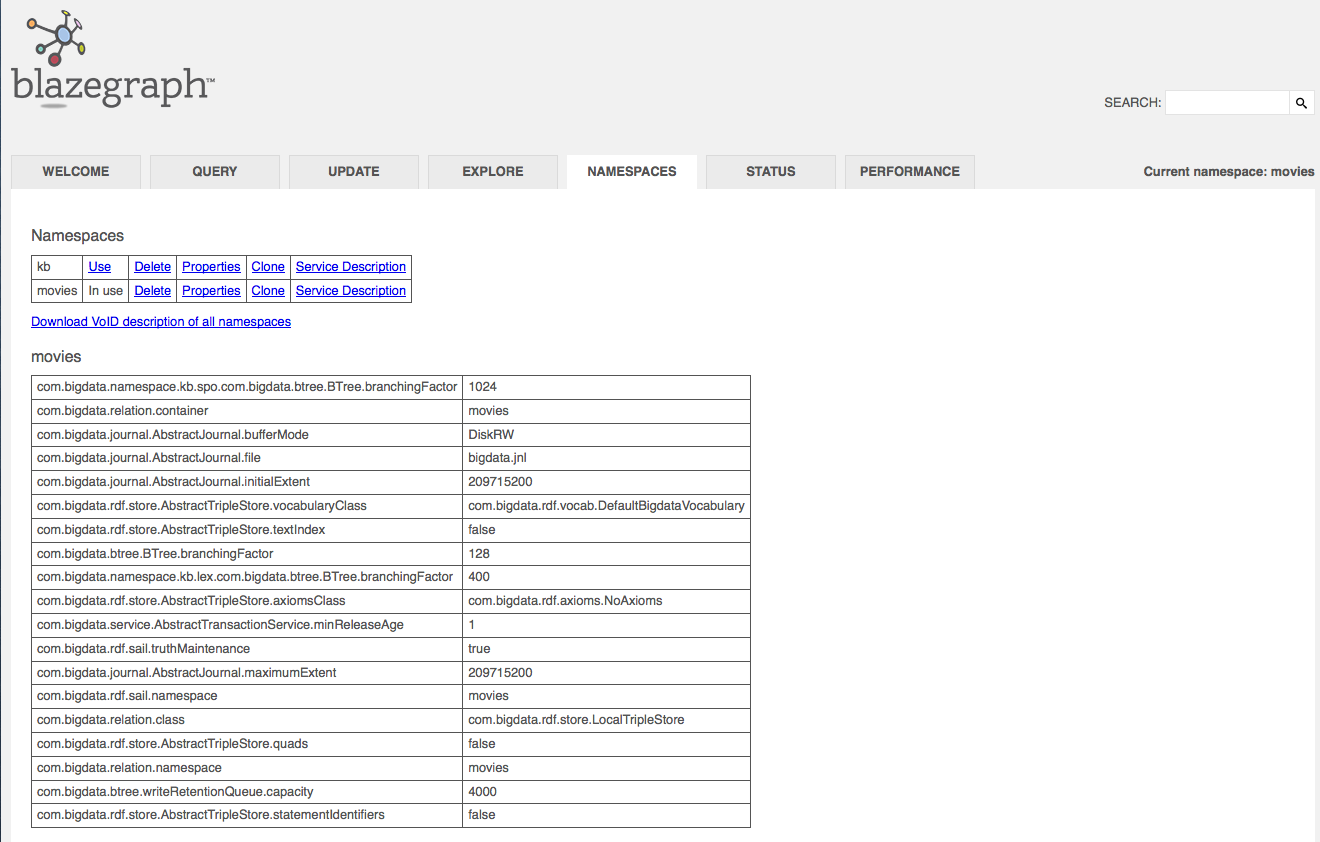
Blazegraph has a very clean and simple admin interface, that uses http sessions to keep information between tabs. It allows you to create new datasets, load data, run SPARQL queries and explore data. It also has some performance and status tools, allowing you to view currently running queries no matter where they came from.
Sesame
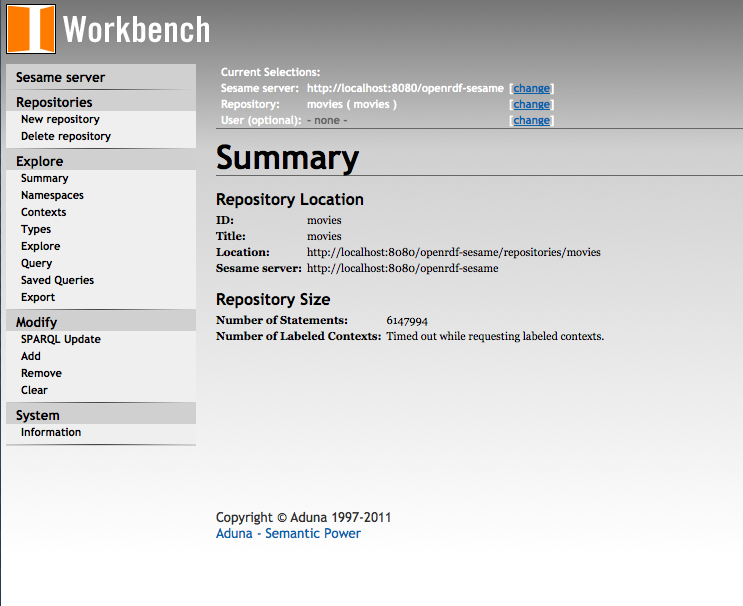
The sesame admin inferface comes from the workbench WAR file. It allows you to create various types of graphs, load data, explore data and run queries.
Virtuoso
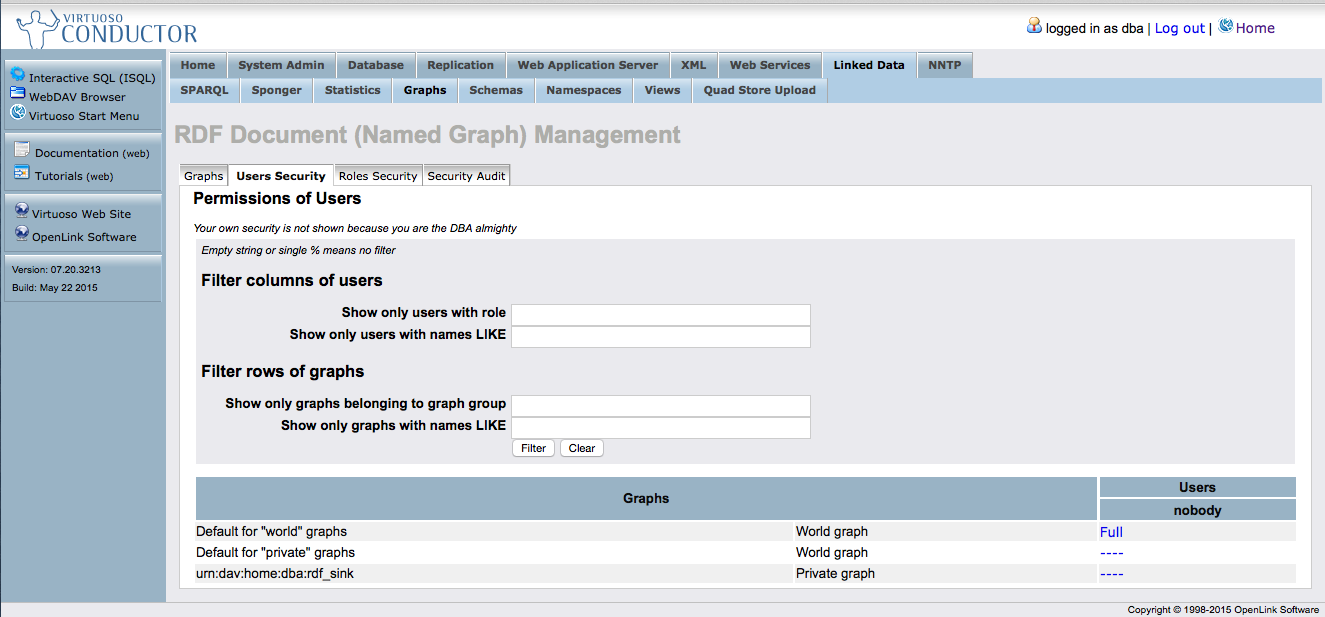
Compared to all the others the virtuoso admin interface is very confusing, and this is probably because virtuoso is not just a triple store, but a relational database with a linked data component built in. It can create graphs, and has tools to query and load them, but it is very heavy and prone to not working.
Data Loading
The first step after finishing basic set up of the triple stores was to attempt to load something into them and start querying it. I was looking for a decently sized dataset with data that was not hard to understand to people outside the discipline. I settled on the Linked Movie Database dataset as it fulfilled all these requirements. It is a set of roughly 600k triples in the N-triples format.
<http://data.linkedmdb.org/resource/interlink/36322> <http://data.linkedmdb.org/resource/oddlinker/linkage_run> <http://data.linkedmdb.org/resource/linkage_run/1> .
<http://data.linkedmdb.org/resource/film_cut/30648> <http://xmlns.com/foaf/0.1/page> <http://www.freebase.com/view/guid/9202a8c04000641f800000000b4dedc5> .
<http://data.linkedmdb.org/resource/performance/25260> <http://data.linkedmdb.org/resource/movie/performance_character> "" .
<http://data.linkedmdb.org/resource/performance/160947> <http://data.linkedmdb.org/resource/movie/performance_actor> "Chris Messina" .
<http://data.linkedmdb.org/resource/performance/171014> <http://data.linkedmdb.org/resource/movie/performance_film> "Saikin-rett\u00C5\u008D" .
<http://data.linkedmdb.org/resource/film/22085> <http://xmlns.com/foaf/0.1/page> <http://www.freebase.com/view/guid/9202a8c04000641f8000000006b56bdb> .
<http://data.linkedmdb.org/resource/film/38811> <http://data.linkedmdb.org/resource/movie/initial_release_date> "1982" .
<http://data.linkedmdb.org/resource/film/97822> <http://data.linkedmdb.org/resource/movie/filmid> "97822"^^<http://www.w3.org/2001/XMLSchema#int> .
<http://data.linkedmdb.org/resource/film_film_distributor_relationship/7336> <http://data.linkedmdb.org/resource/movie/film_film_distributor_relationship_distributor> "Metro-Goldwyn-Mayer" .
<http://data.linkedmdb.org/resource/film/37528> <http://xmlns.com/foaf/0.1/page> <http://www.rottentomatoes.com/alias?type=imdbid&s=0164961> .With this 800MB file in hand I attempted to load it directly into the various stores with varying degrees of success.
Fuseki
Fuseki allowed for multiple files to be uploaded at once and even gave a progress bar, however it did not load the raw file properly and gave an error message with no additional information. I assumed there was a format problem inside the file so I went about converting it to another format. To accomplish this I used python’s RDFLib which can read various RDF file formats and allow you to perform queries against an internal graph that it builds. It can then also serialize this graph back out into many formats. However, RDFLib also refused to read the file due to special characters in the URIs. I set about using sed and a custom python script to correct all the issues and finally loaded the n-triples file into RDFLib and then re-serialized it back out into Turtle format. I tried uploading the Turtle file into Fuseki and it took about 15min but worked and correctly updated its triple count.
from rdflib import Graph
g = Graph()
g.parse("m5.nt", format="nt")
with open("movies.ttl", "w") as f:
f.write(g.serialize(format="turtle"))Blazegraph
Blazegraph allows you to upload files directly but limits them to some size over HTTP, however it also allows you to point to a file on the local file system and load from there. After moving the original file over to the server it spent about 10 minutes loading it and reported back that it now had 600k triples.
Sesame
Sesame allows files to be directly uploaded through workbench. Having had so many problems with the raw file in Fuseki I tried uploading the corrected n-triple file that worked with RDFLib and after roughly 15min it reported back that it was loaded and updated its number of triples.
Virtuoso
Virtuoso also allows file uploading through the admin interface. I uploaded the ‘corrected’ n-triples file and it appeared to work. However it does not give a count of triples loaded anywhere, and the only way to tell was to attempt to query against it, which only worked halfway, but more on that in the next section.
Data Exploration
The ability to run queries from the admin interface and explore the data contained in the store is an important function for these triple stores as it replaces the functionality of browsing schemas in a traditional relational database.
Fuseki
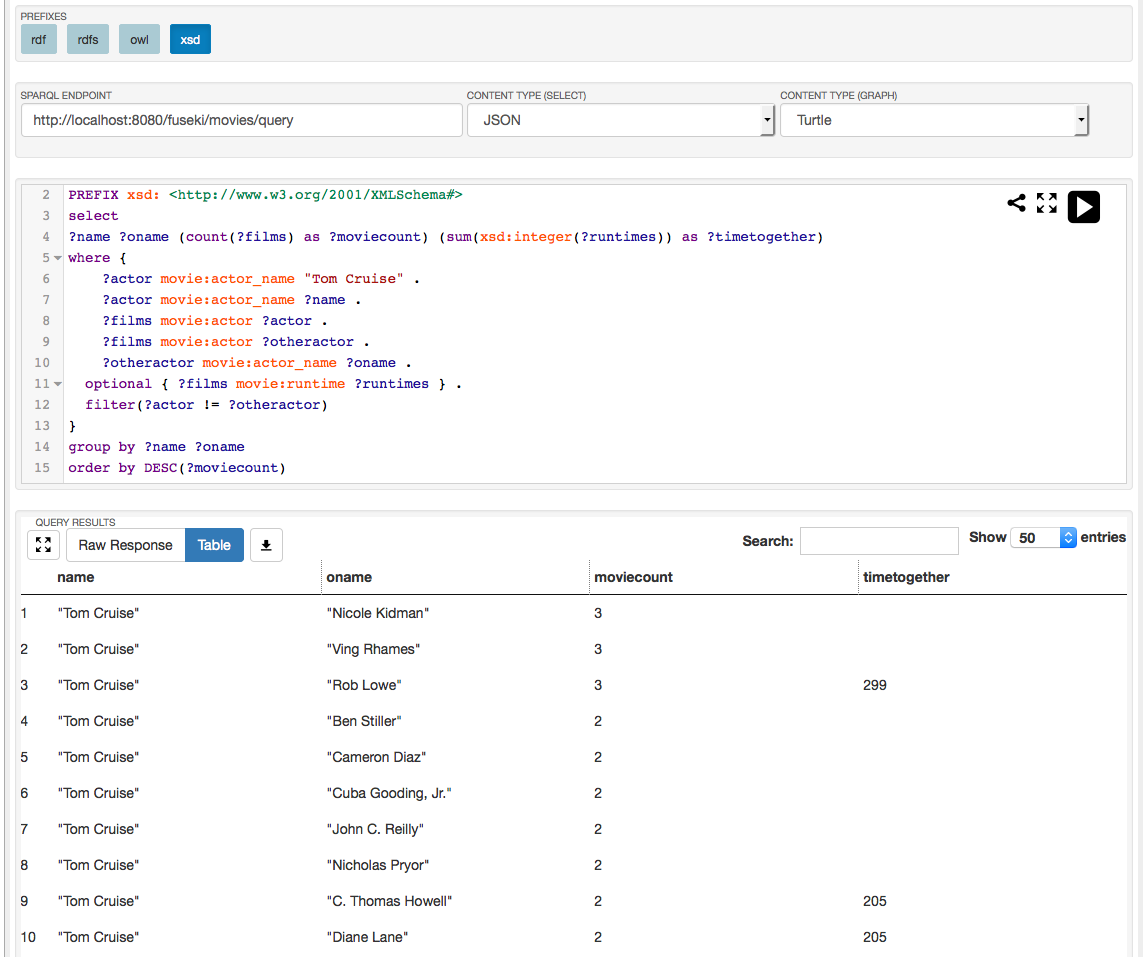
Fuseki has a very polished query interface, which supports syntax highlighting, syntax checking, common prefix addition and the ability to turn a query into a URL to request it from the REST interface. However, despite all the positives it has some large drawbacks. First it lacks any sort of exploration meaning you will need to craft a new query each time you want to explore what your data looks like. Secondly, it appears to send all data returned from a query back to the client for client-side javascript to handle the pagination, this can cause problems when queries return large datasets back.
Blazegraph
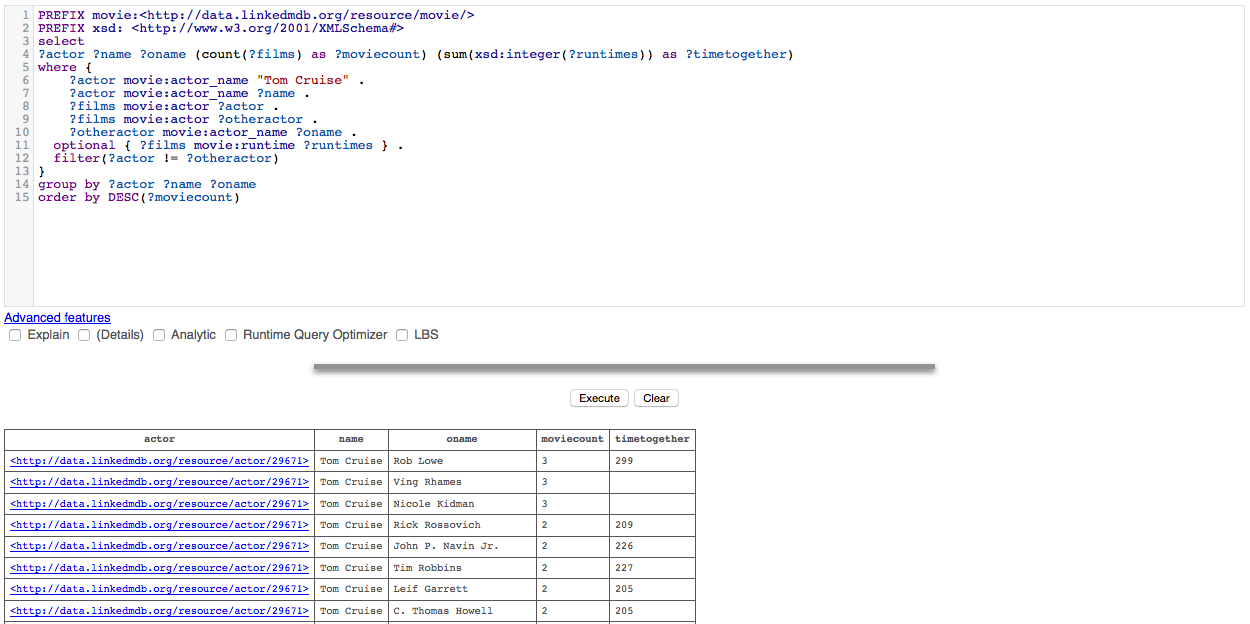
Blazegraph also supports syntax highlighting in its query editor, however it lacks syntax checking or the ability to URL-ize the query. It does pagination of queries on the server-side and handles query running in an HTTP session, meaning you can move off the query tab to explore other sections of the admin interface, such as the excellent status page where you can view information about currently running queries. Also it keeps a log of recently run queries and the time they took to complete, meaning you can do a small amount of performance testing and run queries again. Query results are returned such that non-literals link to the data exploration side of the admin interface.
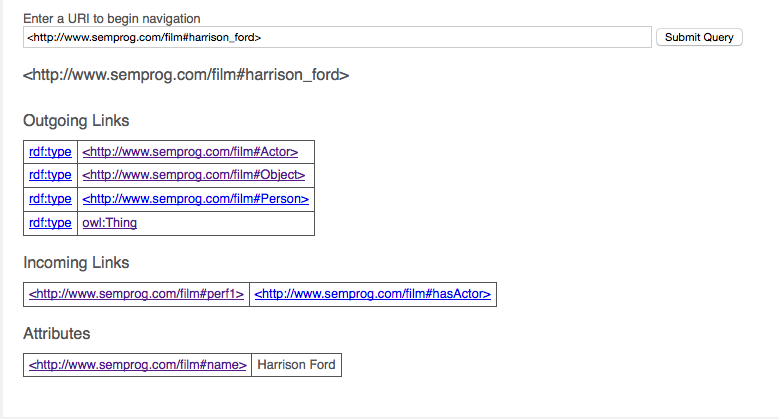
Once you are in the data exploration side you can see outgoing and incoming links as well as attributes of the current node. These are all links meaning you can further explore the graph by clicking. The queries being run to generate this are logged in the status page and can be viewed just like a normal query.
Sesame
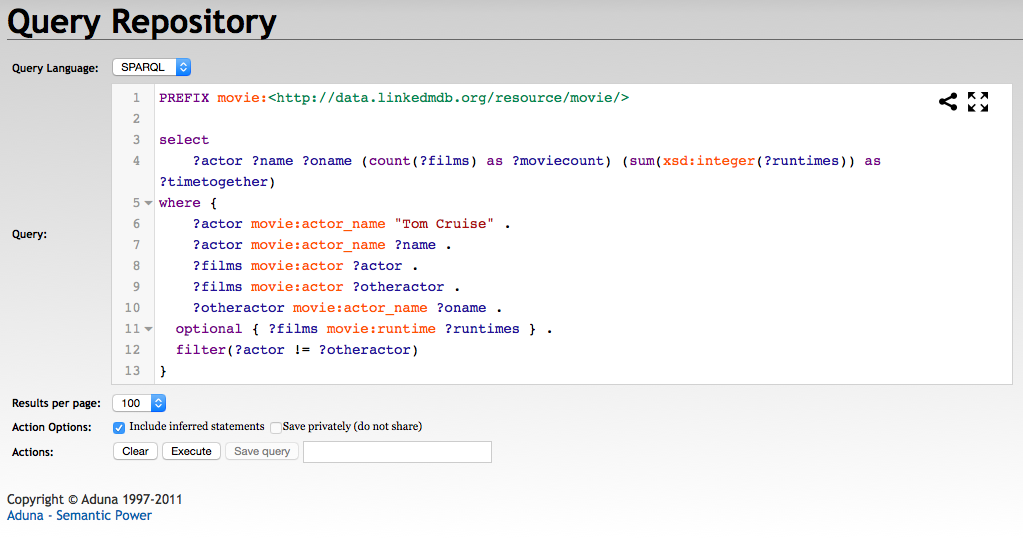
Sesame has a query interface very similar to Fuseki with the same javascript editor, however it does not parse the results with client-side javascript. Much like blazegraph it returns results as URLs into its own exploration interface.
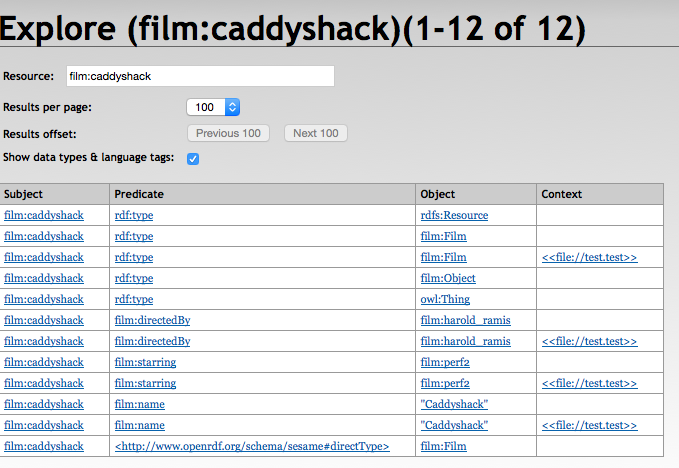
Sesame shows the same information as blazegraph it just does not break it out as nicely. When working with OWL classes though it will display a super/sub-class structure, which can be useful for finding problems. Sesame has one additional feature over blazegraph, which is an extra button on the query results and exploration allowing you to follow a URL to its original server if you are working with data from an external source.
Virtuoso
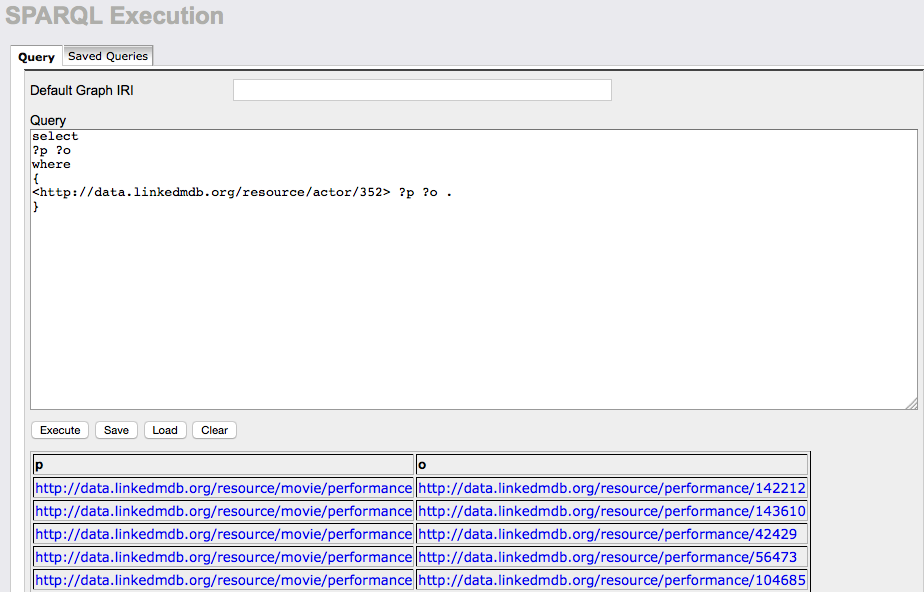
While investigating virtuoso’s query interface I was having trouble finding a query that would run, and this was when I discovered that virtuoso had either not loaded all of the data or discarded a significant amount of it. The query interface for virtuoso is very basic with no syntax highlighting or any features to explore the data. I could have mis-configured the graph or uploaded the file incorrectly, but without any good documentation to follow I’m not sure what is the problem here. Because of this problem I will not consider virtuoso past this point, but may update this at a later date if I can figure out the problem.
REST
For my purposes this was the most important feature of these triple stores as it would be the only way the application would interact with the data. I had need of both the ability to query and update the data in the store from a client-side javascript application. Unfortunately due to the nature of RDF working directly client to triple store is difficult. In traditional RESTful APIs collections of members can be retrieved and then all properties of each member can be retrieved independently. Because of the graph nature of RDF neither of these works quite the same from a REST point of view. Take for example a graph storing information about books with this simple structure.
@prefix book: <http://example.com/book/> .
@prefix author: <http://example.com/author/> .
book:snow_crash book:name "Snow Crash";
book:published 1992;
book:author author:stephenson .
book:diamond_age book:name "Diamond Age" ;
book:published 1995;
book:author author:stephenson .
author:stephenson author:fullname "Niel Stephenson" .You can picture a simple API for viewing this data with a traditional REST framework.
/books -> list of all book ids
/book/:id -> properties of the book identified by :id
And then a second set of endpoints for authors.
/authors
/author/:id
This sort of REST API is not possible only using the triple stores I have been investigating. They all have slightly different REST capabilities, but all share a few major shortcomings.
Blazegraph
Blazegraph allows you to either use Sesame to serve its REST endpoint or the built in NanoSparqlServer, these are the features of the NanoSparqlServer. This allows for data to be loaded through various formats and the ability to directly execute arbitrary SPARQL queries. This is a problem because it forces anyone else attempting to use the system to know the layout of our data, and removes any ability to do security as the entire graph is exposed to the internet.
With that in mind if we had the URI for a book and wanted to query the information for it there would be two options. We could either run a naive query asking for all triples with the book as the subject, or a well defined query to return exactly the information we want.
curl localhost:8080/bigdata/namespace/books/sparql \
--data-urlencode "query=select * where{<http://example.com/book/diamond_age> ?p ?o}" \
--data-urlencode "format=json"This naive query produces results that are somewhat difficult to work with, as you need loop through the bindings and keep a list of values that you have found.
{
"head" : {
"vars" : [ "p", "o" ]
},
"results" : {
"bindings" : [ {
"p" : {
"type" : "uri",
"value" : "http://example.com/book/author"
},
"o" : {
"type" : "uri",
"value" : "http://example.com/author/stephenson"
}
}, {
"p" : {
"type" : "uri",
"value" : "http://example.com/book/name"
},
"o" : {
"type" : "literal",
"value" : "Diamond Age"
}
}, {
"p" : {
"type" : "uri",
"value" : "http://example.com/book/published"
},
"o" : {
"datatype" : "http://www.w3.org/2001/XMLSchema#integer",
"type" : "literal",
"value" : "1995"
}
} ]
}
}With knowledge of the data you can produce a much more refined SPARQL query to pull just the information that you want.
PREFIX book:<http://example.com/book/>
PREFIX author:<http://example.com/author/>
select ?name ?published ?author_name where{
book:diamond_age book:name ?name .
book:diamond_age book:published ?published .
book:diamond_age book:author ?author .
?author author:fullname ?author_name .
}curl localhost:8080/bigdata/namespace/books/sparql \
--data-urlencode "query=PREFIX book:<http://example.com/book/> PREFIX author:<http://example.com/author/> select ?name ?published ?author_name where{ book:diamond_age book:name ?name . book:diamond_age book:published ?published . book:diamond_age book:author ?author . ?author author:fullname ?author_name .}" \
--data-urlencode "format=json"{
"head" : {
"vars" : [ "name", "published", "author_name" ]
},
"results" : {
"bindings" : [ {
"author_name" : {
"type" : "literal",
"value" : "Niel Stephenson"
},
"name" : {
"type" : "literal",
"value" : "Diamond Age"
},
"published" : {
"datatype" : "http://www.w3.org/2001/XMLSchema#integer",
"type" : "literal",
"value" : "1995"
}
} ]
}
}However, this approach requires embedding large SPARQL queries in your client-side applications or require anyone using your data to have knowledge of SPARQL and your data layout. This is not ideal.
Fuseki
Fuseki implements the same SPARQL endpoints as Blazegraph and returns things in the same format.
Sesame
In addition to support for HTTP SPARQL queries like Blazegraph and Fuseki sesame has support for asking for individual subjects, predicates or objects using the following syntax.
curl -G localhost:8080/openrdf-sesame/repositories/books/statements \
--data-urlencode "subj=<http://example.com/book/diamond_age>" \
-H "Accept: application/rdf+json"Results in the following json block are somewhat like the naive query seen above as it is returning full URIs and would require additional queries to find all the information that we want to display the basic information of this book.
{
"http://example.com/book/diamond_age" : {
"http://example.com/book/author" : [
{
"value" : "http://example.com/author/stephenson",
"type" : "uri"
}
],
"http://example.com/book/name" : [
{
"value" : "Diamond Age",
"type" : "literal",
"datatype" : "http://www.w3.org/2001/XMLSchema#string"
}
],
"http://example.com/book/published" : [
{
"value" : "1995",
"type" : "literal",
"datatype" : "http://www.w3.org/2001/XMLSchema#integer"
}
]
}
}RDF Feature Support
When I speak of RDF features I mean any possible inference or reasoning that the triple store can do based on any ontologies that have been loaded into the store. Inferences and reasoning are similar but quite distinct things. Inference generally refers RDF level types and classes being represented in the stored triples, while reasoning is applying an OWL reasoner to support more advanced constructs such as owl:sameAs.
Fuseki
The Jena engine has the largest coverage of both reasoning engines and inference models. Both reasoning and inference are performed with query modification or virtual triples. This results in slower queries with heavy reasoning or inference, but allows great flexibility.
Blazegraph and Sesame
Blazegraph and Sesame both only support RDF level materialized inference. This results in very fast processsing of queries with slightly slower loading speeds, and a certain intractability to the RDF class structure of the data.
Performance
Performance testing was done using the Lehigh University Benchmark. This is a generated dataset and a set of 14 SPARQL queries that test the performance and reasoning/inference capabilities of a triple store.
| Query | Fuseki | Blazegraph | Sesame |
|---|---|---|---|
| 1 | 0.79 | 0.08 | 0.08 |
| 2 | 208.62 | 0.05 | 0.01 |
| 3 | 0.07 | 0.01 | 0.01 |
| 4 | 15.47 | 0.02 | 0.06 |
| 5 | 0.24 | 0.06 | 0.03 |
| 6 | 0.22 | 0.21 | 0.08 |
| 7 | 59.68 | 0.02 | 0.30 |
| 8 | 2.84 | 0.30 | 1.16 |
| 9 | 17.46 | 0.05 | 0.05 |
| 10 | 0.06 | 0.03 | 0.01 |
| 11 | 0.03 | 0.02 | 0.01 |
| 12 | 0.01 | 0.02 | 0.00 |
| 13 | 0.19 | 0.02 | 0.00 |
| 14 | 0.07 | 0.05 | 0.05 |
Fuseki
Multiple results are listed here for different levels of reasoning and inference with Jena.
OWL MEM MICRO_RULE_INF
This is described as an optimised rule-based reasoner with OWL full rules. It has the slowest performance of any rule set or environment, however it is the only thing that returns the correct results for all queries.
Time - 306.289955139
Total Results - 25671
| Query# | Runtime | Results |
|---|---|---|
| 1 | 0.790 | 4 |
| 2 | 208.6 | 0 |
| 3 | 0.073 | 6 |
| 4 | 15.47 | 34 |
| 5 | 0.243 | 719 |
| 6 | 0.224 | 7790 |
| 7 | 59.68 | 67 |
| 8 | 2.840 | 7790 |
| 9 | 17.46 | 3101 |
| 10 | 0.067 | 4 |
| 11 | 0.338 | 224 |
| 12 | 0.016 | 15 |
| 13 | 0.191 | 1 |
| 14 | 0.075 | 5916 |
RDFS_MEM_RDFS_INF
RDFS inference mode is performing the same level of inference as the other two triple stores, however this is performed in memory as opposed to materializing the triples at the time of data load resulting in much worse performance.
Time - 249.190382004
Total Results - 19797
| Query# | Runtime | Results |
|---|---|---|
| 1 | 0.282 | 4 |
| 2 | 191.8 | 0 |
| 3 | 0.089 | 6 |
| 4 | 0.044 | 34 |
| 5 | 0.385 | 719 |
| 6 | 0.218 | 5916 |
| 7 | 42.85 | 59 |
| 8 | 1.961 | 5916 |
| 9 | 11.19 | 1227 |
| 10 | 0.046 | 0 |
| 11 | 0.011 | 0 |
| 12 | 0.008 | 0 |
| 13 | 0.038 | 0 |
| 14 | 0.081 | 5916 |
RDFS_MEM
Here no reasoning is used which get much closer to testing the raw performance of the triple store.
Time - 56.2234978676
Total Results - 5926
| Query# | Runtime | Results |
|---|---|---|
| 1 | 0.187 | 4 |
| 2 | 55.64 | 0 |
| 3 | 0.034 | 6 |
| 4 | 0.011 | 0 |
| 5 | 0.013 | 0 |
| 6 | 0.009 | 0 |
| 7 | 0.009 | 0 |
| 8 | 0.010 | 0 |
| 9 | 0.010 | 0 |
| 10 | 0.009 | 0 |
| 11 | 0.011 | 0 |
| 12 | 0.010 | 0 |
| 13 | 0.009 | 0 |
| 14 | 0.221 | 5916 |
Blazegraph
Blazegraph was run in triple mode with inference turned on for this graph. Blazegraph had the best performance and returned more correct results than sesame which was running in the same inference mode.
Time - 1.15243792534
Total Results - 20022
| Query# | Runtime | Results |
|---|---|---|
| 1 | 0.086 | 4 |
| 2 | 0.056 | 0 |
| 3 | 0.016 | 6 |
| 4 | 0.029 | 34 |
| 5 | 0.060 | 719 |
| 6 | 0.211 | 5916 |
| 7 | 0.025 | 59 |
| 8 | 0.305 | 5916 |
| 9 | 0.053 | 1227 |
| 10 | 0.036 | 0 |
| 11 | 0.024 | 224 |
| 12 | 0.026 | 0 |
| 13 | 0.025 | 1 |
| 14 | 0.050 | 5916 |
Sesame
Sesame had a problem returning duplicate results, which can be seen here with the greatly inflated number of results returned.
Time - 3.34652090073
Total Results - 117311
| Query# | Runtime | Results |
|---|---|---|
| 1 | 0.088 | 16 |
| 2 | 0.012 | 0 |
| 3 | 0.011 | 24 |
| 4 | 0.065 | 544 |
| 5 | 0.039 | 1397 |
| 6 | 0.083 | 5916 |
| 7 | 0.017 | 472 |
| 8 | 1.160 | 94656 |
| 9 | 0.054 | 2454 |
| 10 | 0.010 | 0 |
| 11 | 0.008 | 0 |
| 12 | 0.009 | 0 |
| 13 | 0.008 | 0 |
| 14 | 0.054 | 11832 |
Adding DISTINCT to the query brough the numbers much closer to the other triple stores, however it will stll missing data on query 11 and query 13, when compared to inference mode in Jena and Blazegraph.
Time - 1.57800793648
Total Results - 19797
| Query# | Runtime | Results |
|---|---|---|
| 1 | 0.033 | 4 |
| 2 | 0.012 | 0 |
| 3 | 0.009 | 6 |
| 4 | 0.017 | 34 |
| 5 | 0.025 | 719 |
| 6 | 0.071 | 5916 |
| 7 | 0.016 | 59 |
| 8 | 1.060 | 5916 |
| 9 | 0.083 | 1227 |
| 10 | 0.008 | 0 |
| 11 | 0.007 | 0 |
| 12 | 0.007 | 0 |
| 13 | 0.007 | 0 |
| 14 | 0.069 | 5916 |
Production Readiness
For a system to be used in production some form of security and a system to backup data are very important. Security can be handled at two levels either system wide through another process or at a graph level by the triple store itself, either of these could be useful depending on needs. In the same way backups could either be handled by the triple store itself or through an external process that copies files.
Fuseki
Fuseki can create graph backups directly from the admin interface, these are created as gzipped n3 files of the entire graph stored on the server. To restore them either a new graph can be created and that file can be directly loaded or the current graph can be purged and then reloaded from the file.
Fuseki uses Apache Shiro for security and this allows various user authentication methods, and allows graph level security.
Blazegraph
The Blazegraph admin interface allows for datasets to be cloned, but this button does not appear to function, at least any way that I could find. Ontop of that I could not find any files that could be backed up manually.
Blazegraph has no method for graph level security and thus relies on the Java application server to provide security.
Sesame
The Sesame workbench alows for a graph to be exported through various formats, however this is very slow and comes over uncompressed, which results in far larger files to be generated and transfered. Sesame has no support for graph level security and also relies on the application server.